Building Better Code with Data Structures
A Beginner's Guide to Boosting Performance and Productivity.



Table of contents
- The Importance of Data Structures in Programming
- Exploring the Categories of Data Structures
- A. Linear Data Structures
- B. Non-Linear Data Structures
- Conclusion
Have you ever wondered how search engines like Google can quickly find relevant results? The answer lies in the clever use of data structures.
Data Structure is a way of organizing and storing data in a computer’s memory in a way that enables efficient access and modification of data. On a computer, we have lots of data to organize and store. The efficient way of storing these data and how fast or slow we can access them are what we refer to as data structures.
The Importance of Data Structures in Programming
The following are some reasons why data structures are important:
Efficiency
Data structures are designed to optimize the use of a computer’s processing power and memory. This helps us work with large amounts of data quickly and efficiently.
Reusability
One good feature of good code is the ability to reuse it as many times as needed. Data structures offer that as well. It helps developers reuse their code across different programs. This feature of data structures makes them flexible, saves time, and also ensures that robust and reliable systems are built.
Scalability
As data grows, programmers tend to find a way to handle this increased data. Data structures allow programmers to handle large amounts of data without having to sacrifice the performance of their systems.
Exploring the Categories of Data Structures
Data structures can be categorized into two.
These are:
A. Linear Data Structures
Linear data structures are characterized by elements that are arranged in a sequential order. Elements in linear Data Structures are accessed in a particular order, either in a backward or forward direction.
Some commonly used Linear Data structures include the following:
1. Arrays
Arrays are collections of elements of the same data type stored in contiguous memory locations. Contiguous in the sense that a block of continuous memory addresses is allocated to store an array element. The elements are stored adjacent to each other in memory, which allows faster access to any element in the array.
The index in an array identifies each element and represents its position in the array. Arrays can be one-dimensional, two-dimensional, or multi-dimensional.
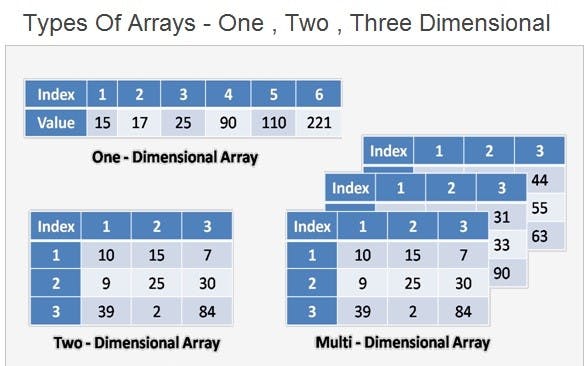
Arrays can be classified into two categories: static arrays and dynamic arrays.
Static Arrays: This is an array with a fixed size allocated to it at compile-time that remains constant throughout the execution of the program. The size is specified when it is declared and cannot be changed at runtime.
#include <stdio.h>
int main() {
// Declare a static array of size 5
int static_array[5];
// Initialize values in the static array using a loop
for (int i = 0; i < 5; i++) {
static_array[i] = (i + 1) * 10;
}
// Accessing values from the static array
printf("The value at index 0 is: %d\n", static_array[0]);
printf("The value at index 2 is: %d\n", static_array[2]);
return 0;
}
In the above example, I declared a static array of size 5 and initialized its values using a for loop I then accessed specific values from the array using index notation and printed them to the console.
Dynamic arrays: Dynamic arrays are different from static arrays because they can change size while a program is running, and they are often implemented using pointers. This makes them more flexible than static arrays, allowing for better use of memory and more versatility in programming.
#include <stdio.h>
#include <stdlib.h>
int main() {
// Declare a pointer to an integer
int *dynamic_array;
// Dynamically allocate memory for a dynamic array of size 5
dynamic_array = (int*) malloc(5 * sizeof(int));
// Initialize values in the dynamic array using a for loop
for(int i = 0; i < 5; i++) {
dynamic_array[i] = (i + 1) * 10;
}
// Accessing values from the dynamic array
printf("The value at index 0 is: %d\n", dynamic_array[0]);
printf("The value at index 2 is: %d\n", dynamic_array[2]);
// Free the dynamically allocated memory
free(dynamic_array);
return 0;
}
In the above code, I declare a pointer to an integer and dynamically allocate memory for a dynamic array of size 5 using malloc(). I then initialized the values in the dynamic array using a for loop that iterates over the indices of the array. Each value is initialized to the product of (i + 1) and 10. This will initialize the first 5 values of the dynamic array to 10, 20, 30, 40, and 50, respectively.
Advantages of using Array data structure
Random Access: Elements in an array can be accessed randomly by using their index. This allows for quick access and makes it ideal for instances where elements need to be modified frequently.
Sorting and searching can easily be done with the use of arrays.
Implementation: Arrays are straightforward to implement in data structures. They are easy to declare, initialize, and work with.
Memory Efficiency: As mentioned earlier, one of the things we look for in data structures is the efficiency of memory, and arrays allow that since a fixed amount of memory is allocated to work with them.
Disadvantages of using Arrays
Fixed-size: Static arrays have a fixed size, which is determined at compile time. This makes the size unchangeable at runtime, which is not helpful because in instances where the programmer might want to allocate more space, it makes it impossible, and in cases where the spaces or size allocated are not fully used, it leads to wastage of memory, which we would not want as programmers.
Inserting and Deleting elements in an array is inefficient: This is because both insertion and deletion in an array require the shifting of subsequent elements. In instances where the array is large, this wouldn’t be a suitable data structure to use.
Arrays play a critical role as a fundamental data structure for programmers who use them to store and manipulate collections of data, such as numbers, characters, and objects.
2. Linked Lists
Linked lists are a type of linear data structure consisting of a collection of nodes, with each node containing two sections: one for the data or value, and the other for a pointer or link to the next or previous node. Programmers rely on linked lists primarily for data that can change size during runtime.
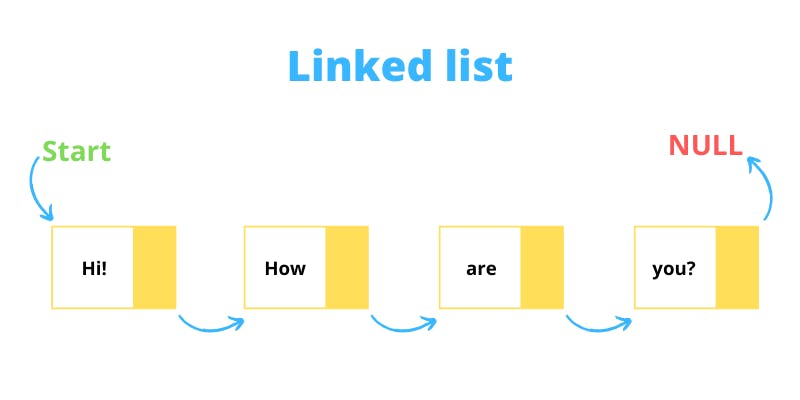
The following are the main types of linked lists:
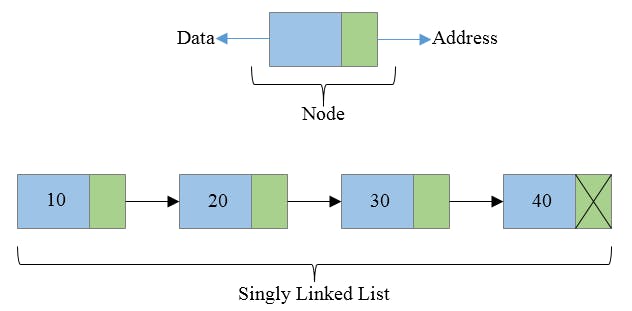
Singly Linked List: A singly linked list is a collection of nodes, each of which contains two pieces of information:
The data that the node holds (which could be a number, string, or any other value)
a reference to the next node in the list
The first node in the list is called the head, and the last node in the list has a reference to null to indicate the end of the list.
To traverse the list, you start at the head and follow the reference to the next node, then follow that node's reference to the next node, and so on until you reach the end of the list.
You can add or remove nodes from a singly linked list by updating the references of neighboring nodes to point to the new node or the node that comes after the removed node, respectively.
Overall, a singly linked list provides a simple way to store and manipulate collections of data in a linear fashion.
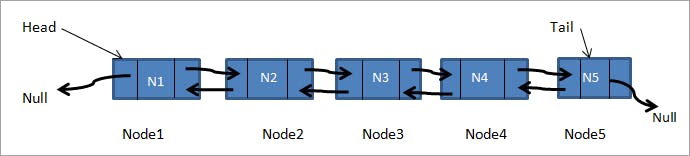
Doubly Linked List: A doubly linked list is a type of linked list where each node has two pointers, one pointing to the next node and the other pointing to the previous node in the list. This means you can traverse the list in both directions, either from the beginning to the end or from the end to the beginning.
Circular linked list: This is a type of linked list in which the last node in the list points back to the first node, forming a circular structure. This means you can traverse the list endlessly in a loop.
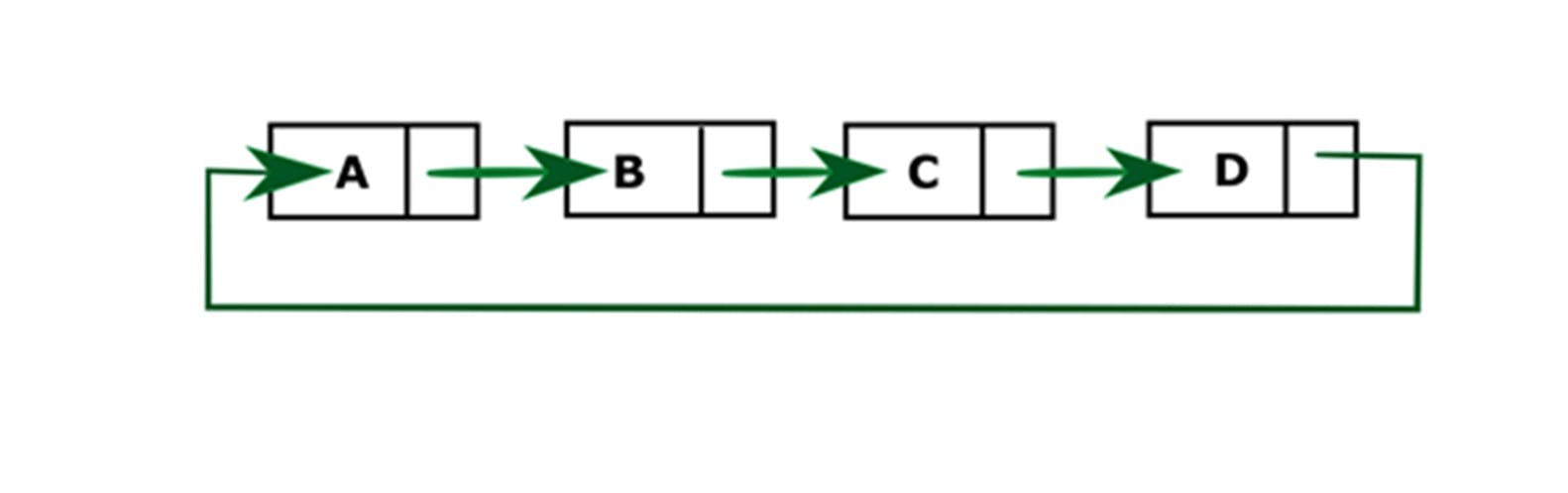
Circular linked lists are useful for applications where you need to continuously cycle through a set of data, such as a rotating buffer.
Advantages of using Linked list data structure
Flexibility: Linked lists are dynamic and can be easily resized at runtime.
Insertion and Deletion: Adding or deleting a node in a linked list is a constant-time operation, irrespective of the size of the list.
Memory Efficiency: Linked lists only allocate memory when needed, making them more memory-efficient compared to arrays.
Traversal: Linked lists can be traversed in either direction, making them more flexible compared to stacks and queues.
Disadvantages of using Linked List data structure
Random access is inefficient: Unlike arrays, linked lists do not provide direct access to elements. You have to start at the head and traverse the list one node at a time to find the desired element.
Extra memory: Linked lists require extra memory for storing the pointers that link the nodes together. This overhead can become significant for large lists.
Implementation: Linked lists can be more complex to implement compared to arrays.
In summary, linked lists can offer a tradeoff between size, efficiency of deletion and insertion, but at the cost of random access and increased complexity.
3. Stacks
Stacks are a type of data structure that follows the Last-In-First-Out (LIFO) principle, meaning the last element inserted into the stack is the first one to be removed.
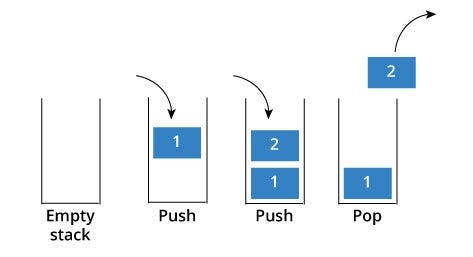
The following are some key features of stacks:
a. Push Operations: This adds an element to the top of the stack.
b. Pop Operation: This removes the top element from the stack.
The Plate Analogy: A Simple Way to Grasp Stacks
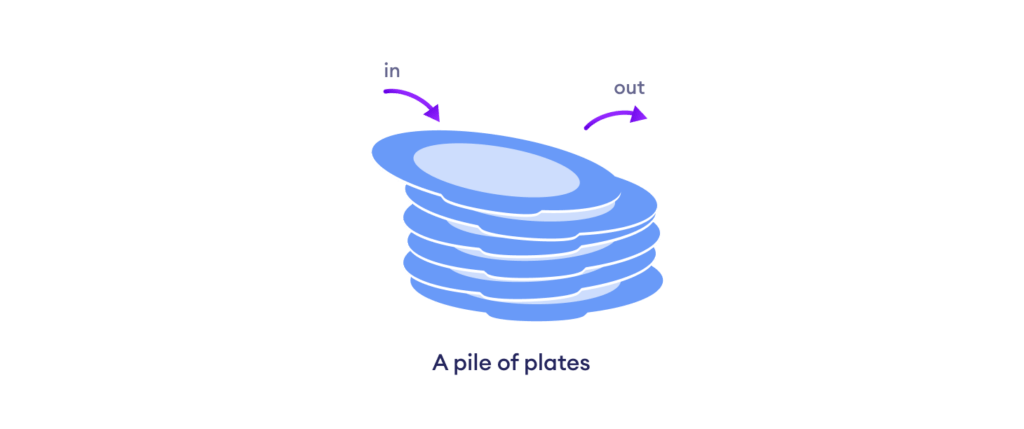
Imagine a stack of plates in a kitchen cabinet. The stack of plates is a lot like a stack data structure in computer science.
When you add a plate to the stack, you place it on top of the previous plate. This is similar to the "push" operation in a stack, which adds an element to the top of the stack. When you need to remove a plate, you take it off the top of the stack. This is similar to the "pop" operation in a stack, which removes the top element from the stack.
The most important aspect of the plate principle to keep in mind is that plates may only be added to or taken away from the top of the stack. Without first removing all the plates above it, you cannot add a plate to the middle of the stack or remove a plate from the bottom of the stack. This is comparable to the stack data structure's LIFO (Last-In-First-Out) characteristic.
Advantages of Stacks
Efficient Insertion and Deletion of Elements.
Versatile and easy to implement.
Disadvantages of Stacks
When using arrays to implement stacks, the size is fixed, which can limit the flexibility of the data structure. As previously mentioned, a fixed-size array may not be desirable in certain implementations of data structures.
Stacks have limited functionality compared to other data structures.
4. QUEUES
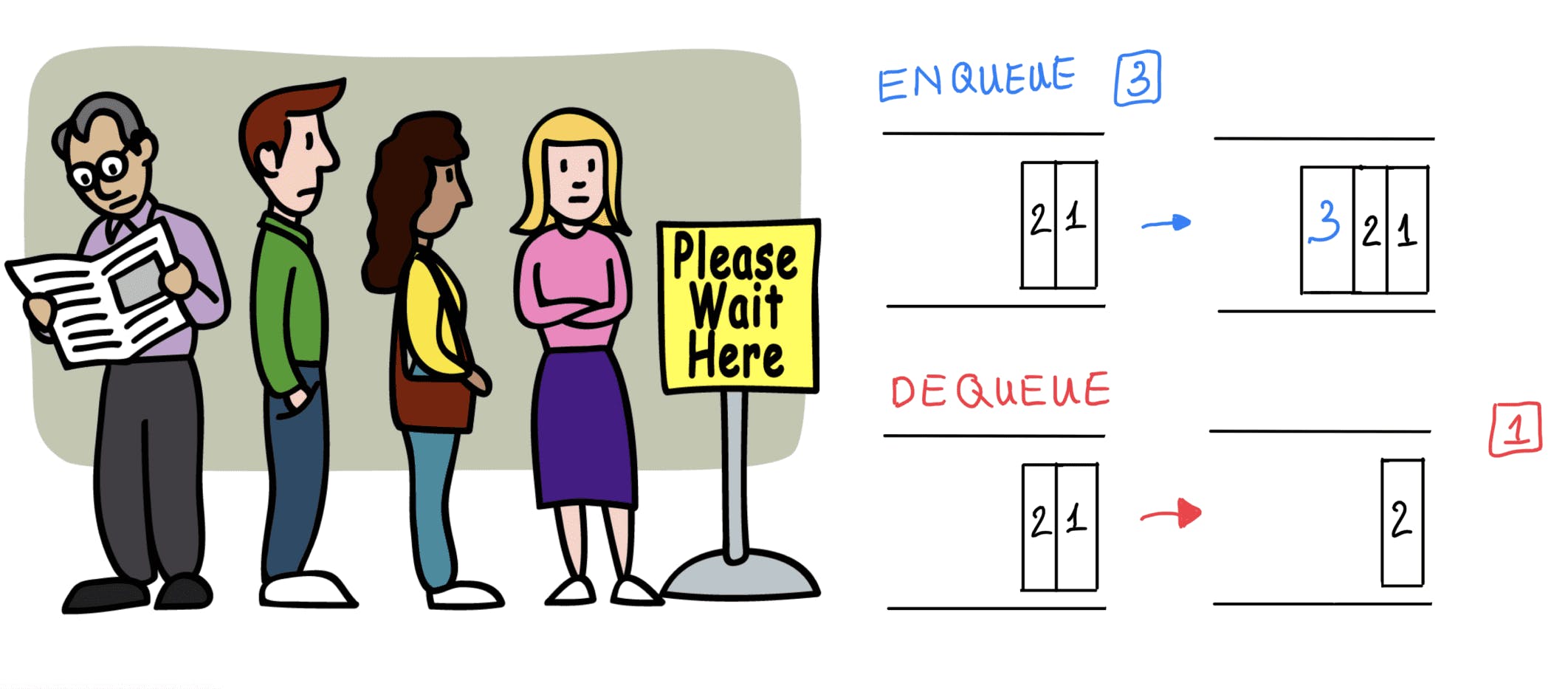
Queues are a type of data structure that follows the "First-In-First-Out" (FIFO) principle, meaning the first element inserted into the queue is the first one to be removed.
It is easy to understand the queue data structure by comparing it to a line of passengers waiting to board a bus or a movie theater.
A line of people has a front and a back, just like a queue. The back of the queue is where new customers enter, while the front is where customers are served or let out of the line first. This is comparable to a queue's "enqueue" and "dequeue" operations, which add elements to the back of the queue and remove them from the front, respectively.
You cannot skip ahead and join the middle of the line in a real-world line, nor can you exit from the middle without passing through everyone in front of you. Similarly to this, removing an element from the middle of a queue data structure requires first removing every element in front of it.
The First-In-First-Out (FIFO) principle, which states that the first element added to the queue is the first one deleted, is another crucial characteristic of a queue. This is comparable to how the first person to get in line is served first.
Key Features of Queues
Enqueue and Dequeue Operations: The two main operations supported by queues are enqueue, which adds an element to the back of the queue, and dequeue, which removes the front element from the queue.
Queue Implementation using Arrays and Linked Lists: Queues can also be implemented using both arrays and linked lists. In an array-based implementation, a fixed-size array is used to store the queue elements, while in a linked list-based implementation, a series of linked nodes are used to represent the queue.
Advantages of Queues
Efficient insertion and deletion of elements
Easy implementation and versatility.
Disadvantages of Queues
Fixed-size array implementation
Limited functionality compared to priority queues and heaps.
Queues have applications in computing, including job scheduling and networking protocols. They are also used in everyday life, such as when waiting in lines.
B. Non-Linear Data Structures
Non-linear data structures are characterized by elements that are not arranged in sequential order. Elements in non-linear data structures are accessed in a non-linear way, with multiple paths to traverse the data.
Some commonly used non-linear data structures include the following:
a) Trees
A tree is a data structure that represents a hierarchical structure. Nodes in a tree are connected by edges, and each node contains a value and can have zero or more child nodes. Trees are commonly used for searching, sorting, and representing hierarchical data in computer science.
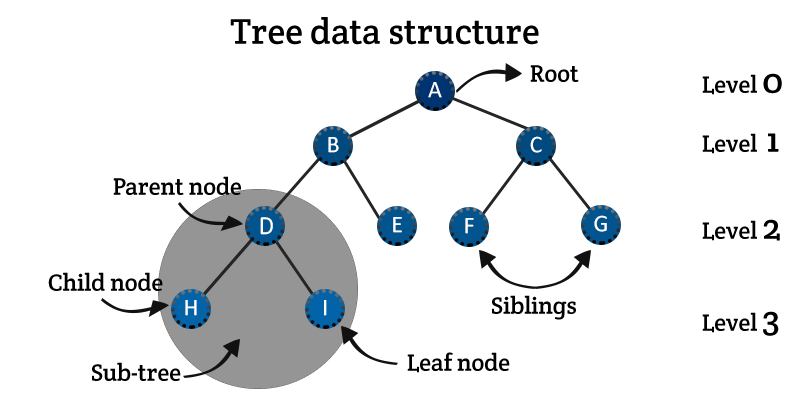
Types of Trees:
Binary Trees
Binary Search Trees
AVL Trees etc.
Advantages of Trees
Trees can be used to store data in a form that makes it possible for quick searches and the addition of new pieces.
Data that is sorted: For some applications, trees that keep data sorted, such as binary search trees, might be valuable.
Efficiency: Trees can be used to efficiently carry out a variety of activities, like identifying the most or least number of elements or all the elements that fall within a given range.
Disadvantages of Trees
Complexity: The complexity of tree operations can be higher than that of other data structures, such as arrays or lists.
Memory overhead: Trees can require more memory than other data structures due to the overhead of storing pointers to child nodes.
Slower traversal: Traversing a tree can be slower than traversing a simple linear data structure, such as an array or a list.
b) Hash Tables
A hash table is a data structure that uses a hash function to map keys to array indices. It allows fast access to data and is commonly used for storing and retrieving data in computer programs, especially when large amounts of data need to be stored and accessed quickly.
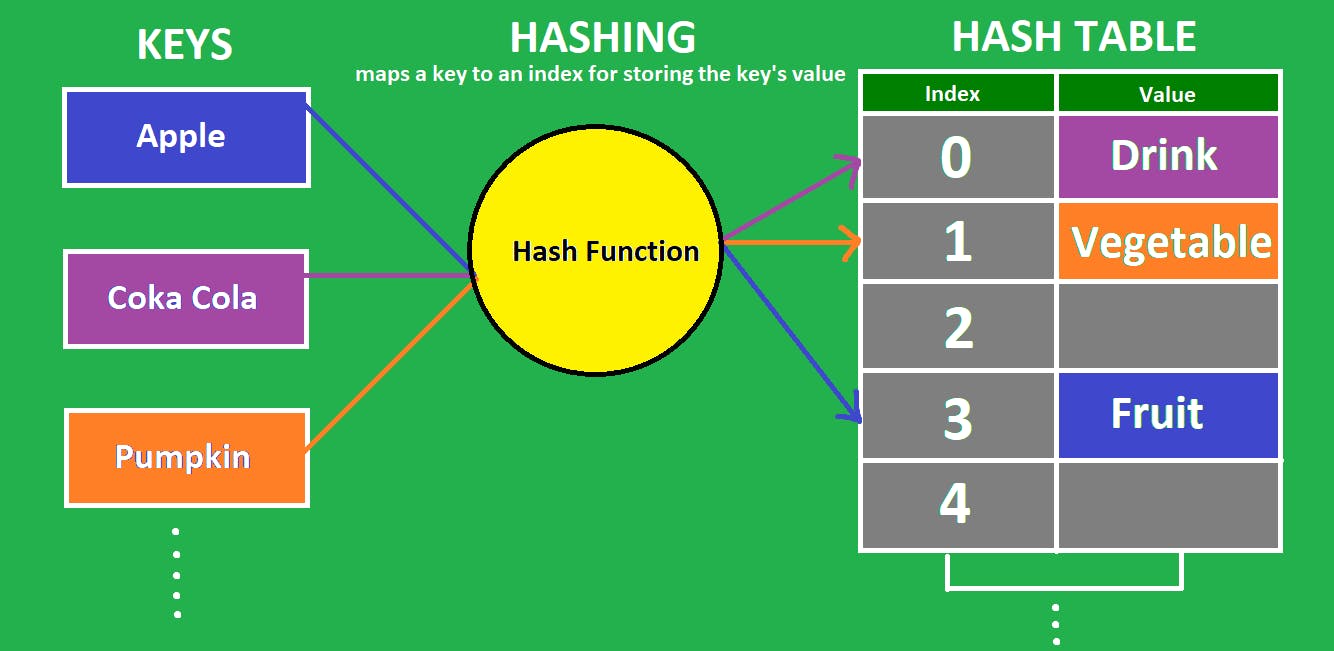
They are particularly useful when large amounts of data need to be stored and accessed quickly. However, hash tables can have collisions, which occur when multiple keys map to the same array index, resulting in slower access times.
Advantages of Hash Tables
Fast retrieval: Hash tables allow for fast retrieval of data based on a key, as the hash function can quickly determine the index into the array where the data is stored.
Constant-time operations: In many cases, hash table operations such as insertion, deletion, and lookup can be performed in constant time.
Space efficiency: Hash tables can be more space-efficient than other data structures, as they only need to store the data and the hash table array, rather than pointers to child nodes.
Disadvantages of Hash Tables
Collisions: When two keys hash to the same index, a collision occurs, which can slow down hash table operations.
Hash function quality: The quality of the hash function can impact the efficiency of hash table operations and the occurrence of collisions.
No order: Hash tables do not maintain any ordering of the data, which can be a disadvantage for certain applications.
Conclusion
In conclusion, data structures are a fundamental aspect of computer science and programming. They enable programmers to organize and store data in an efficient way that optimizes the use of a computer's processing power and memory. The two main categories of data structures are linear and non-linear, each with its advantages and disadvantages.
It's important to note that other non-linear data structures were not covered in this discussion, such as graphs, and heaps. These data structures are commonly used in computer science and programming for solving a variety of problems, such as pathfinding, optimization, and data organization.
Understanding the basics of data structures is crucial for any programmer, as it helps build robust and reliable systems that can handle large amounts of data efficiently. By choosing the appropriate data structure for a particular problem, programmers can ensure that their programs are efficient, scalable, and easy to maintain.
Thank you for taking the time to read my article. If you have any questions or would like to get in touch with me, please feel free to reach out. You can follow me on Twitter @Yaw__Amponsah for updates on my latest articles and other computer science-related topics. Additionally, you may send an email to the address listed, yawamp27@gmail.com, and I will do my best to respond as promptly as possible. Your feedback is valuable to me, and I welcome the opportunity to discuss any topics related to computer science and programming. Thank you again for reading, and I look forward to hearing from you.